 info@biz4group.com
info@biz4group.com 






















































How to Build a Generative AI Solution from Designing to Deployment?
Keynotes
1. Generative AI relies on quality data and architecture selection for effective model training.
2. Techniques like web scraping and synthetic data generation enhance dataset diversity.
3. Continuous evaluation, user feedback, and iteration are crucial for model refinement.
4. Regular updates, monitoring, and collaboration ensure robust maintenance and iteration.
5. Adhering to best practices ensures building effective generative AI solutions for diverse applications.
Generative AI, a transformative branch of artificial intelligence, empowers the creation of novel content autonomously. Harnessing generative AI solutions has become imperative for innovation across industries. This blog serves as a comprehensive guide to building AI models, applications, and software, specifically focusing on generative AI solutions. From conceptualization to deployment, we delve into the intricacies of crafting AI systems that leverage generative capabilities. Whether you're an entrepreneur or an enterprise, learn how to develop AI applications that utilize generative techniques to produce unique and impactful outputs.
Understanding Generative AI
Generative AI, a subset of artificial intelligence, focuses on creating content autonomously, revolutionizing various industries. It utilizes neural networks to generate data, such as text, images, and music, based on patterns learned from vast datasets. With its ability to produce novel and diverse outputs, generative AI solutions are transforming traditional approaches to content creation and problem-solving. Let's now look at the types of models used to get a complete generative AI solution.
Types of Generative AI Models You Should Know
Generative AI models encompass a diverse array of techniques and architectures designed to create content autonomously. From text generation to image synthesis, each type of model offers unique capabilities and applications. This section explores five prominent types of generative AI models, including Generative Adversarial Networks (GANs), Large Language Models, Diffusion Models, Variational Autoencoders (VAEs), and Transformer-based Models. Understanding these models is essential for leveraging custom generative AI solutions effectively in various domains. Let's delve into each model's characteristics, applications, and considerations for building AI applications. Let's discuss the models now.
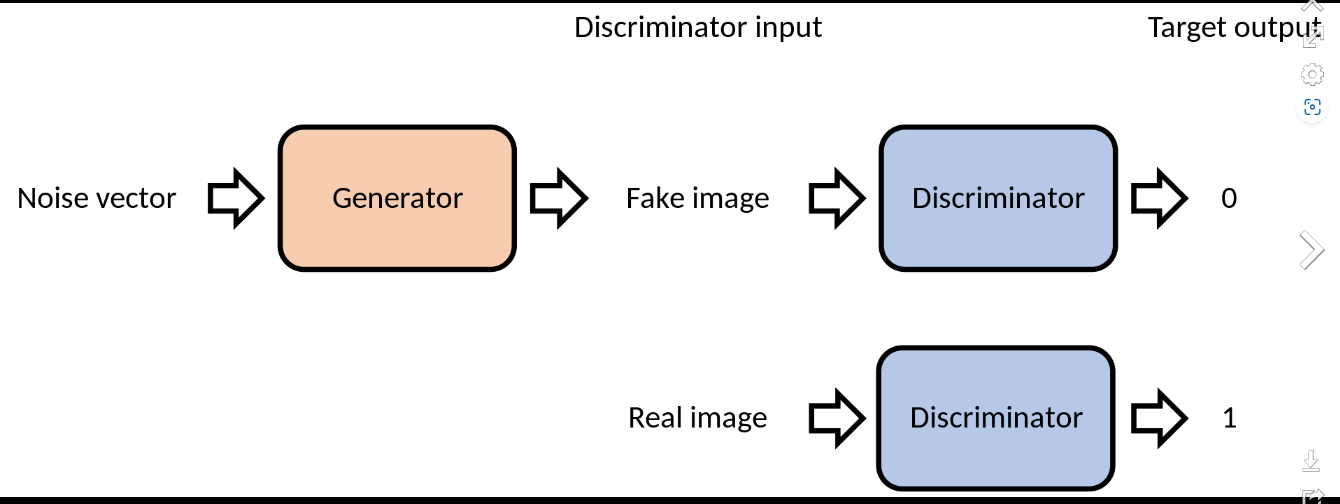
Generative Adversarial Networks (GANs): GANs revolutionize AI by pitting two neural networks against each other: the generator creates synthetic data, while the discriminator distinguishes real from fake. This adversarial process refines the generator's output, generating remarkably realistic data, making GANs ideal for image and text generation tasks. To build a GAN model, developers design the architecture, define loss functions, and train it on datasets. Fine-tuning hyperparameters improves performance, ensuring high-quality outputs for various applications, from image synthesis to content creation.
Large Language Models: These sophisticated NLP systems, like GPT-3, transform text generation tasks by producing human-like text. To build a large language model, developers preprocess text data, choose the model architecture, and fine-tune it on specific tasks. Leveraging transfer learning and massive datasets, these models learn intricate patterns in language, enabling diverse applications such as chatbots, language translation, and content summarization. Building a large language model involves selecting the appropriate architecture, training it on vast datasets, and fine-tuning it for specific tasks, ensuring accurate and coherent text generation. If you are looking to develop such models, consider partnering with a Chatbot Development Company for expertise and efficiency.
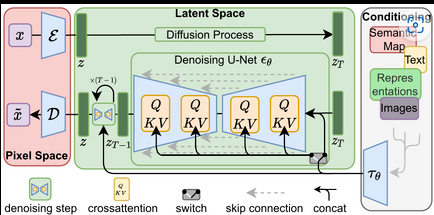
Diffusion Models: Diffusion models estimate complex probability distributions over data, enhancing understanding and synthesis in various domains. To build a diffusion model, developers design the architecture, define loss functions, and train it on datasets. By iteratively refining the data distribution, diffusion models excel in tasks like image synthesis, inpainting, and denoising. Building a diffusion model involves selecting the appropriate architecture, training it on relevant datasets, and evaluating its performance, ensuring high-quality outputs for tasks requiring intricate data distribution estimation.
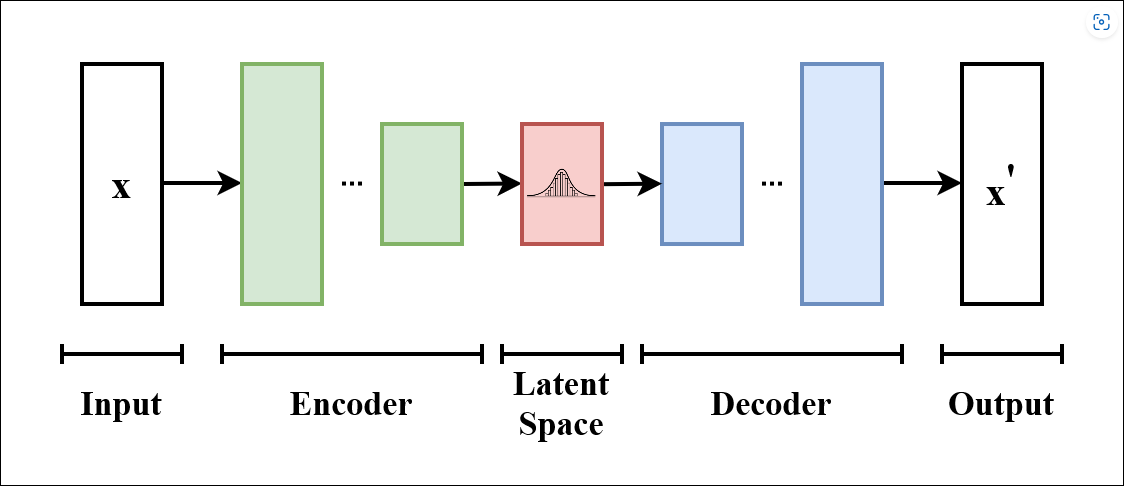
Variational Autoencoders (VAEs): VAEs employ an encoder-decoder architecture to capture and generate complex data distributions, making them versatile in generating diverse outputs. To build a VAE, developers design the architecture, define the loss functions, and train it on datasets. By mapping input data to a lower-dimensional latent space, VAEs generate data with desired characteristics. Building a VAE involves selecting the appropriate architecture, training it on diverse datasets, and fine-tuning it to capture complex data distributions effectively.
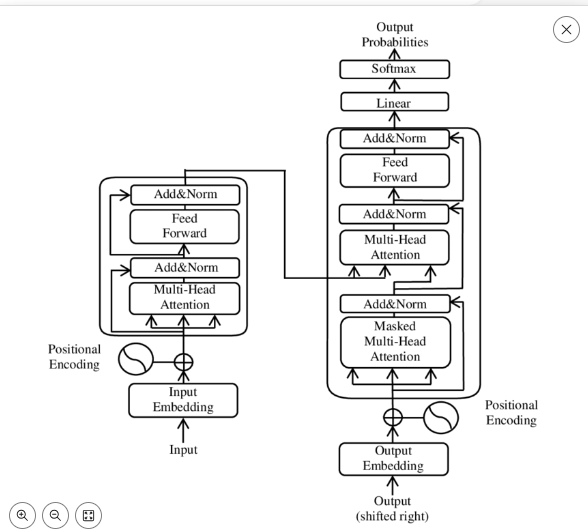
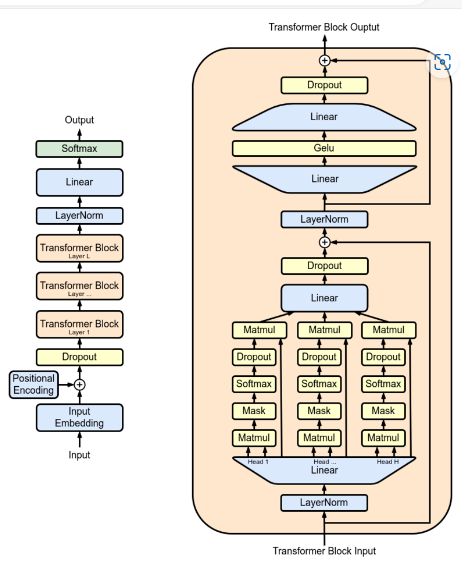
Transformer-based Models: These models leverage self-attention mechanisms to parallelize data processing and capture long-range dependencies within sequences, enhancing performance in various NLP tasks. To build a transformer-based model, developers preprocess text data, design the architecture, and train it on datasets. By attending to relevant parts of the input sequence, transformers excel in tasks like language translation, text generation, and sentiment analysis. Building a transformer-based model involves selecting the appropriate architecture, training it on extensive datasets, and fine-tuning it for specific NLP tasks, ensuring accurate and context-aware text generation.
Applications and Use Cases for Everyone
Generative AI solutions are revolutionizing various industries by automating processes and enhancing productivity. From content generation to personalized recommendations, these applications leverage the power of generative AI to streamline operations and improve user experiences. Let's know some of the top use cases of generative AI.

1. Content Generation
Generative AI automates the creation of diverse content types, including text, images, and music. By analyzing patterns in existing data, generative models can produce original and high-quality outputs, reducing the time and effort required for content creation. Businesses can leverage this technology to develop engaging marketing materials, compelling visual assets, and captivating music compositions, driving creativity and efficiency in content production.
2. Creative Design
Generative AI empowers designers to generate innovative and personalized designs across various domains, including graphic design, architecture, and fashion. By inputting design parameters and preferences, AI models can produce an array of design variations, inspiring creativity and facilitating the exploration of unique concepts. Designers can utilize generative AI solutions to generate mockups, prototypes, and customizations, accelerating the design process and unlocking new possibilities for creative expression.
3. Drug Discovery
Generative AI plays a pivotal role in accelerating drug discovery processes by generating molecular structures and predicting their properties. By analyzing vast datasets of chemical compounds and biological interactions, AI models can identify potential drug candidates with desired therapeutic effects. This enables pharmaceutical companies to expedite the drug development pipeline, reducing costs and improving treatment outcomes for various medical conditions.
4. Personalized Recommendations
Generative AI enables businesses to deliver tailored recommendations and advertisements to users based on their preferences and behavior. By analyzing user data and interaction patterns, AI models can generate personalized content recommendations, product suggestions, and promotional offers, enhancing user engagement and satisfaction. Businesses can leverage generative AI solutions to optimize marketing campaigns, increase sales conversions, and foster long-term customer loyalty.
5. Virtual Assistants
Generative AI powers virtual assistants capable of understanding natural language and providing human-like responses to user queries and commands. By leveraging natural language processing algorithms and conversational AI techniques, virtual assistants can interact with users in real-time, offering assistance, information, and guidance across various tasks and domains. From scheduling appointments to answering questions and performing tasks, generative AI-driven virtual assistants enhance user interaction and experience, improving efficiency and convenience in daily activities.
These diverse applications demonstrate the transformative potential of custom generative AI solutions in streamlining processes, enhancing creativity, and delivering personalized experiences across industries. By leveraging generative AI technologies, businesses can optimize operations, drive innovation, and create value for customers and stakeholders. As we are now aware of its models and use cases, it will be much easier for you to concentrate on developing a generative AI product from scratch. The next topic involves a step-by-step process of creating a product and highlights crucial aspects while discussing the steps.
Building a Generative AI Solution from Start to Deployment
The integration of generative AI solutions has emerged as a cornerstone for innovation and progress. From streamlining business operations to enhancing user experiences, the potential of generative AI is boundless.
This section navigates the intricate process of building and deploying generative AI solutions, offering invaluable insights from conception to implementation. By delving into key methodologies and best practices, organizations can harness the power of generative AI to develop cutting-edge applications and propel their businesses into the future.
Define Problem Statement and Objectives
A. Clarifying the Problem Statement
Define the specific challenge or opportunity that the generative AI solution aims to address. Articulate the problem statement clearly, focusing on key pain points or areas of improvement. Incorporate stakeholder input to ensure alignment with organizational objectives and user needs. A well-defined problem statement serves as a guiding beacon, steering the development process towards tangible outcomes. A good problem statement must include the below-mentioned points to deliver a clear and concise vision behind the software.
1. Identifying Key Challenges: Analyze the current landscape to pinpoint specific pain points or inefficiencies that necessitate the use of generative AI solutions. Consider factors such as manual processes, resource constraints, or limitations in existing systems. By identifying and understanding the challenges, you can tailor the AI model to address these issues effectively, leading to impactful solutions.
2. Understanding User Needs: Engage with stakeholders and end-users to gain insights into their requirements, preferences, and pain points. Conduct interviews, surveys, or workshops to gather qualitative and quantitative data on user expectations. Understanding user needs ensures that the generative AI solution is designed with the end-user in mind, enhancing usability and adoption. By aligning the solution with user preferences, you can maximize its value and impact on the target audience.
3. Scalability and Flexibility: Consider the scalability and flexibility requirements of the generative AI solution to accommodate future growth and adaptability. Assess the potential scalability challenges, such as handling large datasets or increasing user demand, and design the solution architecture to support expansion without compromising performance. Additionally, prioritize flexibility to enable seamless integration with existing systems and accommodate evolving business needs. Scalability and flexibility are essential factors for building a robust and future-proof AI model.
4. Ethical and Regulatory Compliance for AI Development Company: Ensure that the generative AI solution developed by the AI development company adheres to ethical principles and regulatory guidelines governing AI development and deployment. Define ethical considerations, such as fairness, transparency, and accountability, to mitigate potential risks of bias or misuse. Comply with relevant regulations, such as data privacy laws or industry standards, to protect user rights and ensure responsible AI usage. Ethical and regulatory compliance are integral aspects of building trustworthy and socially responsible AI solutions for an AI development company.
5. Resource Allocation and Constraints: Evaluate the available resources, including computational power, budget, and expertise, to determine the feasibility of implementing the generative AI solution. Identify any constraints or limitations that may impact the development process, such as hardware constraints or data availability. Allocate resources efficiently to optimize the performance and cost-effectiveness of the AI model. By considering resource allocation and constraints upfront, you can streamline the development process and ensure the successful deployment of the generative AI solution within the specified constraints.
6. Alignment with Business Objectives: Align the objectives of the generative AI solution with the organization's broader business goals and strategic initiatives. Clearly articulate how the AI model will contribute to achieving business objectives, such as improving efficiency, enhancing customer experience, or driving innovation. Ensure that the development efforts are closely aligned with the organization's mission, values, and long-term vision. By aligning with business objectives, you can secure stakeholder buy-in and maximize the impact of the generative AI solution on business outcomes.
B. Establishing Clear Objectives
Set measurable and achievable objectives that outline the desired outcomes of the generative AI solution. Define success criteria, such as performance metrics or user satisfaction benchmarks, to gauge progress and effectiveness. Objectives should be aligned with the overarching goals of the organization, whether it's enhancing productivity, driving innovation, or AI is improving customer experience. Clear objectives provide a roadmap for development and enable stakeholders to track the project's impact and value.
1. Performance Goals: Define specific performance metrics that the generative AI solution should achieve, such as accuracy, speed, or scalability. Set target benchmarks based on industry standards or organizational requirements to ensure the solution meets or exceeds expectations. Performance goals provide a clear direction for development efforts and enable stakeholders to assess the effectiveness of the AI model in real-world applications.
2. Functional Requirements: Identify the key functionalities and capabilities that the generative AI solution must possess to address the identified problem statement. Determine the desired features, such as image generation, text synthesis, or data augmentation, based on the intended use cases and user requirements. Functional requirements serve as a blueprint for building the AI model and guide the development process toward delivering a solution that meets stakeholders' needs.
3. Defining Objectives: Clearly outline the goals and objectives that the generative AI solution aims to achieve. These objectives should be specific, measurable, achievable, relevant, and time-bound (SMART). Whether it's automating repetitive tasks, enhancing creativity, or improving decision-making processes, defining clear objectives provides a roadmap for the development and deployment of the AI model. Aligning the objectives with organizational priorities ensures that the solution delivers tangible benefits and contributes to overall business objectives.
4. Establishing Success Metrics: Define key performance indicators (KPIs) and success metrics that will be used to evaluate the effectiveness and impact of the generative AI solution. Metrics such as accuracy, efficiency, user satisfaction, and return on investment (ROI) provide quantifiable measures of success. By establishing clear success criteria upfront, you can track progress, measure outcomes, and make data-driven decisions throughout the development and implementation process. These metrics also enable continuous improvement and optimization of the AI model over time.
5. Identifying Target Applications: Explore the diverse range of applications where generative AI solutions can be leveraged to address specific challenges or opportunities. These may include image generation, text synthesis, content creation, design optimization, and more. By identifying target applications, you can tailor the development process to meet the unique requirements of each use case. This ensures that the generative AI solution aligns with the needs of end-users and delivers value across various domains and industries.
6. Understanding Use Cases: Delve into specific use cases within each target application to gain insights into how generative AI can be applied to solve real-world problems. Whether it's generating realistic images for e-commerce, creating personalized content for marketing campaigns, or automating design tasks in architecture and engineering, understanding use cases provides clarity on the practical applications of the AI model. Analyze existing use cases and explore potential scenarios to identify opportunities for innovation and impact.
Identifying Target Applications and Use Cases

Generative AI solutions offer versatile applications across industries, facilitating automation and innovation. From image synthesis for creative design to text generation for content creation, the possibilities are vast. Exploring diverse use cases, such as enhancing user experience through personalized recommendations or automating repetitive tasks, empowers organizations to harness the full potential of generative AI. By identifying specific applications aligned with business objectives, developers can streamline solution development and maximize the impact of generative AI technologies.
Assessing Data Requirements and Availability
Assessing Data Requirements and Availability
| Data Type | Quantity | Quality | Source |
|---|---|---|---|
| Image | High | High | CelebA Dataset |
| Text | Large | High | Open Source |
| Audio | Moderate | High | Kaggle Datasets |
Data Availability
Ensuring the availability of high-quality data is paramount for building effective generative AI solutions. While image datasets like CelebA offer a wealth of labeled images for training image generation models, sourcing large text datasets from open-source repositories facilitates text generation tasks. Additionally, Kaggle datasets provide valuable resources for audio-related projects, although ensuring data quality remains essential. By leveraging diverse datasets from reputable sources, developers can address various application requirements and train robust generative AI models. Access to ample and relevant data sets the foundation for successful AI model development, empowering organizations to harness the full potential of generative AI solutions.
Data Collection and Preparation
High-quality data is the cornerstone of building effective generative AI solutions. The success of an AI model heavily relies on the quality and relevance of the data it's trained on. With accurate and diverse data, AI models can learn to generate realistic outputs, such as images, text, or music, meeting the objectives of the application. Conversely, poor-quality data can lead to biased or inaccurate results, undermining the integrity of the AI system. Therefore, investing time and resources into gathering and curating high-quality data is essential for building robust generative AI models.
Importance of High-Quality Data
High-quality data is the cornerstone of building effective generative AI solutions. The success of an AI model heavily relies on the quality and relevance of the data it's trained on. With accurate and diverse data, AI models can learn to generate realistic outputs, such as images, text, or music, meeting the objectives of the application.
Conversely, poor-quality data can lead to biased or inaccurate results, undermining the integrity of the AI system. Therefore, investing time and resources into gathering and curating high-quality data is essential for building robust generative AI models.
Know the Strategies for Data Collection
1. Web Scraping: Web scraping is a vital strategy for collecting data from various online sources, such as websites and social media platforms. Automated tools are used to extract relevant information, including text, images, and other multimedia content. For instance, scraping images from Instagram provides a vast dataset for training generative AI models, particularly for tasks like facial recognition or image synthesis. By harnessing web scraping techniques, developers can access a wide range of publicly available data to enhance the diversity and richness of their training datasets, ultimately improving the performance of their AI models.
2. Crowdsourcing: Crowdsourcing involves soliciting contributions from a large group of users to generate or annotate data. Platforms like Amazon Mechanical Turk facilitate this process by allowing developers to distribute tasks to remote workers who provide labeled data or feedback. For example, developers can leverage crowdsourcing to annotate images, classify text, or validate generated content. This approach enhances dataset diversity and quality by incorporating human judgment and expertise. Crowdsourcing is particularly useful for tasks where manual annotation or subjective evaluation is required, enabling developers to create more accurate and reliable generative AI solutions.
3. Synthetic Data Generation: Synthetic data generation entails creating artificial data that closely resembles real-world samples. This technique is valuable for augmenting existing datasets or generating data for scenarios where collecting real data is impractical or costly. For instance, developers can use generative models to create synthetic images of human faces, landscapes, or objects, which can be used to supplement training datasets for image generation tasks. By leveraging synthetic data generation, developers can increase dataset diversity, balance class distributions, and mitigate biases, ultimately improving the robustness and generalization capabilities of their AI models.
4. Collaboration with Partners: Collaborating with industry partners or research institutions provides access to specialized datasets that may not be publicly available. By leveraging existing data repositories or domain-specific resources, developers can acquire high-quality data relevant to their AI applications. For example, partnering with a medical research center grants access to medical imaging datasets for training diagnostic AI models. Collaborative efforts enable developers to leverage domain expertise, validate model performance in real-world scenarios, and accelerate the development of generative AI solutions tailored to specific industries or use cases.
5. Data Purchase: Data purchase involves acquiring datasets from third-party providers specializing in specific domains or industries. These datasets are often curated, annotated, and quality-checked, making them valuable resources for AI model training. For instance, developers can purchase datasets of financial transactions for training fraud detection algorithms or healthcare records for medical diagnosis applications. While data purchase may incur costs, it provides access to high-quality data that meets regulatory standards and industry requirements. By investing in relevant datasets, developers can expedite the development process and build AI models with enhanced accuracy and reliability.
Processing Technique for Data Cleaning and Normalization
Data Cleaning is essential in building AI models like generative AI solutions. For instance, in image generation applications, removing duplicate or low-quality images ensures high-quality training data. Feature Scaling is crucial to prevent numerical features from dominating others during training. Scaling pixel values in images to a range of 0 to 1 prevents dominance and ensures balanced learning. One-Hot Encoding converts categorical variables like image labels into binary vectors, enabling efficient processing by AI models. In text generation tasks, converting words into binary vectors allows the model to understand categorical data, enhancing its accuracy and effectiveness.
1. Data Cleaning: Ensuring dataset integrity by removing duplicate or irrelevant entries, correcting errors, and handling missing values. For example, in image generation projects, eliminating duplicate images or those with low resolution ensures high-quality training data.
2. Feature Scaling: Scaling numerical features to a similar range to prevent certain features from dominating others during model training. For instance, in AI software development for financial analysis, scaling features like income and expenditure to a common range prevents bias towards larger values.
3. One-Hot Encoding: Encoding categorical variables into binary vectors to represent each category as a separate feature. In building AI systems for natural language processing, one-hot encoding converts words into vectors, enabling the model to understand and process textual data effectively.
4. Text Tokenization: Breaking down text data into smaller units (tokens) like words or characters for further processing. For example, in sentiment analysis applications, text tokenization separates sentences into individual words, allowing the model to analyze the sentiment associated with each word.
5. Image Normalization: Rescaling pixel values to a common range (e.g., 0 to 1) and applying transformations like rotation or flipping for data augmentation. In image recognition tasks, normalization ensures consistent pixel values across images, while transformations enhance the model's ability to generalize to different orientations or perspectives.

Choosing the Right AI Architecture
When delving into generative AI solutions, choosing the right AI architecture serves as a critical juncture. With many options available, from Recurrent Neural Networks (RNNs) to Convolutional Neural Networks (CNNs), navigating this landscape requires careful consideration. Understanding the nuances of each architecture is paramount for building AI models tailored to specific tasks. It explores the key factors to consider when selecting the optimal architecture, ensuring the development of robust and effective generative AI systems. But first, it is better to understand the two available AI architectures.
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are a cornerstone of deep learning, especially in image processing tasks. They excel at identifying patterns and features within images, mimicking how the human visual system operates. In this article, we delve into the architecture of CNNs, their hyperparameters, applications, and the role of regularization in enhancing their performance.
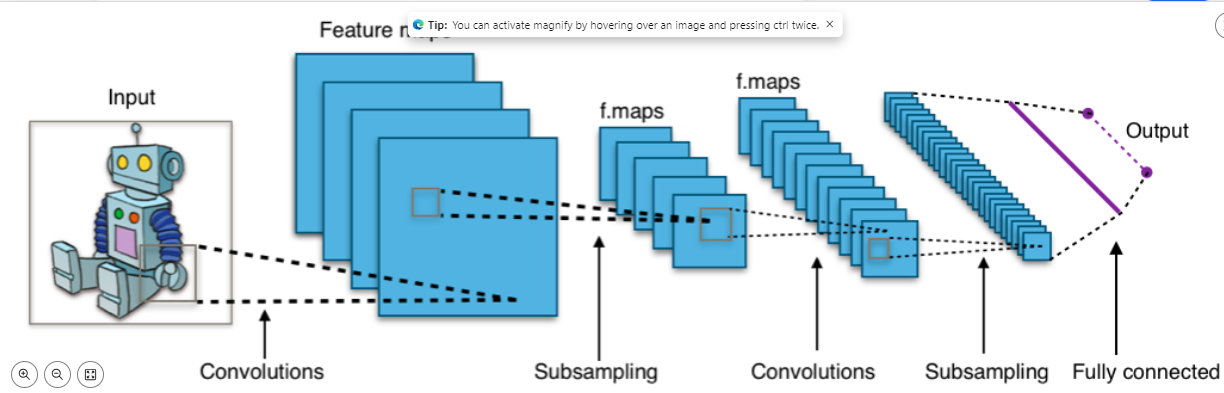
CNN architecture comprises several layers, including convolutional, pooling, ReLU, fully connected, and loss layers. Convolutional layers apply filters to extract features from input images, while pooling layers reduce dimensionality and aid in feature selection. ReLU layers introduce nonlinearity, and fully connected layers perform classification based on extracted features. Loss layers compute the deviation between predicted and actual outputs, facilitating model training.
Hyperparameters like kernel size, padding, and stride govern the behavior of CNN layers, influencing feature extraction and model performance. Regularization techniques such as dropout and data augmentation mitigate overfitting, enhancing generalization to unseen data.
Furthermore, we explore the applications of CNNs across various domains. From image classification and object detection in healthcare and surveillance to document analysis and audio/speech recognition, CNNs power a myriad of real-life applications. Their versatility and effectiveness make them indispensable tools in modern AI systems.
CNNs represent a pivotal advancement in deep learning, enabling machines to interpret and analyze visual data with remarkable accuracy. As research and development in this field continue to evolve, CNNs promise to revolutionize numerous industries and domains, driving innovation and progress in artificial intelligence.
Recurrent Neural Networks (RNNs)
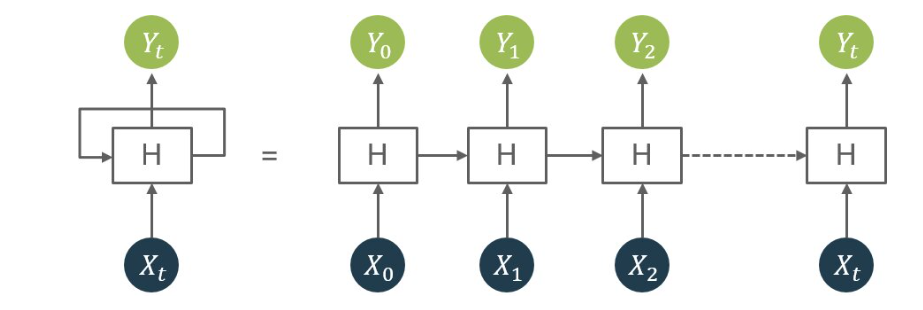
Recurrent Neural Networks (RNNs) are a pivotal tool for processing sequential data, showcasing prowess in tasks like language translation, speech recognition, and text generation. Unlike traditional feedforward networks, RNNs possess a loop structure enabling them to remember information from previous time steps, crucial for capturing long-term dependencies in data. They operate by feeding the output of one time step as input to the next, effectively maintaining a state dependent on past inputs.
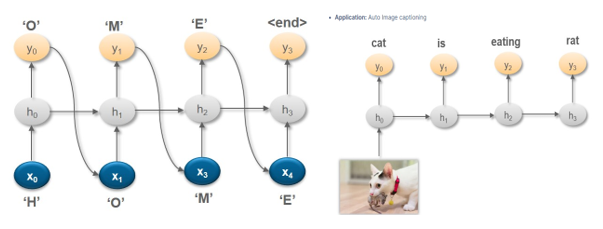
RNNs come in various types: one-to-one, one-to-many, many-to-one, and many-to-many, each tailored for specific tasks. For instance, one-to-many RNNs excel in generating sequences based on a single input, like image captioning. However, training RNNs can be challenging due to the complex loop structure, leading to issues like vanishing or exploding gradients.
To address these challenges, variants like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks have been developed, equipped with mechanisms to tackle the vanishing gradient problem and store long-term dependencies more effectively.
While RNNs offer immense potential in handling sequential data and modeling temporal dependencies, their effectiveness hinges on addressing training complexities and ensuring stability. Nevertheless, their ability to capture intricate patterns over time makes them indispensable in the realm of generative AI solutions.
Considerations for Selecting the Appropriate Architecture
1. Nature of the Input Data: When building an AI model, it's crucial to consider the nature of the input data. For tasks involving sequential data like text or time series, Recurrent Neural Networks (RNNs) are preferred due to their ability to process data sequentially. Conversely, tasks with image data, such as image generation, are better suited for Convolutional Neural Networks (CNNs), which excel at capturing spatial dependencies within images.
2. Complexity of the Task: The complexity of the task at hand is another critical factor in selecting the appropriate architecture for building AI models. More complex tasks may require architectures with additional layers and parameters to capture intricate patterns and relationships effectively. For instance, tasks like generating realistic images with fine details may necessitate a deeper CNN architecture capable of capturing nuanced features and textures.
3. Availability of Computational Resources: Building AI models requires significant computational resources, and it's essential to consider the availability of such resources when selecting the architecture. Architectures that demand more computational power, such as deeper CNNs, may not be feasible in resource-constrained environments or when deploying on edge devices with limited computing capabilities. Thus, it's essential to choose architectures that align with the available resources to ensure efficient model training and deployment.
4. Interpretability Requirements: Interpretability is crucial, especially in applications where understanding the decision-making process of the AI model is essential. RNNs, with their sequential processing nature, are often more interpretable than CNNs for tasks involving sequential data. For example, in text generation tasks, explaining the decision-making process of a model based on RNN architecture is more straightforward due to its sequential nature. This consideration is vital when building AI models for applications where interpretability is a priority.
By carefully considering these factors, developers can select the most appropriate architecture for building AI models that meet the specific requirements of their tasks and applications. These considerations ensure that the chosen architecture aligns with the nature of the data, complexity of the task, available computational resources, and interpretability requirements, ultimately leading to the development of effective and efficient AI solutions.
Examples of Architectures for Different Types of Generative AI Tasks
Various generative AI tasks require different architectures tailored to their specific data and objectives. Below is a table showcasing examples of architectures commonly used for different generative AI tasks:
| Generative AI Task | Example Architecture |
|---|---|
| Text Generation | Recurrent Neural Networks (RNNs) |
| Image Generation | Convolutional Neural Networks (CNNs) |
| Music Generation | Long Short-Term Memory (LSTM) Networks |
| Speech Synthesis | WaveNet |
This table provides a glimpse into the diverse range of architectures utilized in generative AI tasks, highlighting the importance of selecting the appropriate architecture based on the task at hand.
Read More
1. 7 Ways AI Chatbot Can Improve Banking and Financial Services
2. The Role of AI Chatbots in Modern Marketing and Sales
Model Training and Evaluation
Model training and evaluation stand as critical phases ensuring the effectiveness of generative AI solutions. From configuring the architecture to assessing performance metrics, this process shapes the model's ability to generate high-quality outputs. By understanding how to build AI models and leveraging generative AI solutions, developers can create robust applications. Let's delve into the intricacies of model training and evaluation, exploring techniques to optimize performance and achieve desired results. Let’s look at the various aspects under model training and evaluation.
Configuring the Model Architecture
In the journey of building a generative AI solution, one of the pivotal steps is configuring the model architecture. This step lays the groundwork for how the AI system will operate and generate outputs. Here's a detailed look at how to configure the model architecture effectively:
1. Understand the Task: Before diving into model architecture, it's essential to clearly understand the task at hand. Whether it's text generation, image synthesis, or any other application, defining the task will guide the selection of the appropriate architecture.
2. Selecting the Architecture: Depending on the nature of the task, different architectures may be more suitable. For text generation, architectures like Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, or Transformer models like GPT-3 are commonly used. On the other hand, for image synthesis, architectures like Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) might be preferred.
3. Layer Configuration: Once the architecture is chosen, it's time to configure the layers of the model. This involves deciding the number of layers, the type of activation functions, and the size of each layer. Experimentation with different configurations may be necessary to find the optimal setup for the specific task.
4. Hyperparameter Tuning: Hyperparameters play a crucial role in model performance. Parameters such as learning rate, batch size, and dropout rate need to be fine-tuned to achieve the best results. Techniques like grid search or random search can be employed to systematically explore the hyperparameter space.
5. Regularization Techniques: To prevent overfitting and improve generalization, regularization techniques like dropout or L2 regularization can be applied. These techniques help the model generalize better to unseen data and produce more reliable outputs.
Training the Model on Collected Data
With the model architecture configured, the next step is to train the model on the collected data. This phase involves feeding the model with input data and iteratively adjusting its parameters to minimize the error between the predicted and actual outputs. Here's a guide on how to effectively train the model:
1. Data Preprocessing: Before training the model, it's essential to preprocess the data to ensure it's in a suitable format. This may involve tasks such as normalization, scaling, or one-hot encoding, depending on the type of data and the chosen architecture.
2. Splitting the Data: The collected data should be divided into training, validation, and test sets. The training set is used to train the model, the validation set is used to tune hyperparameters and monitor performance, and the test set is used to evaluate the final model performance.
3. Training Process: During the training process, the model is presented with batches of input data, and the parameters are updated using optimization algorithms like Stochastic Gradient Descent (SGD) or Adam. The training process continues for multiple epochs until the model converges to a satisfactory level of performance.
4. Monitoring Performance: Throughout the training process, it's crucial to monitor the model's performance on the validation set. Metrics like loss function values, accuracy, or other task-specific metrics can be used to assess performance and adjust as needed.
Evaluating Model Performance and Iterating as Needed
Once the model is trained, it's time to evaluate its performance and iterate as needed to improve results. Here's how to effectively evaluate the model:
1. Performance Metrics: Depending on the task, various performance metrics can be used to evaluate the model. For text generation, metrics like perplexity or BLEU score may be used, while for image synthesis, metrics like FID score or Inception Score are commonly employed.
2. Qualitative Evaluation: In addition to quantitative metrics, qualitative evaluation is also essential. Visual inspection of generated outputs can provide insights into the model's capabilities and shortcomings. Human evaluation through user studies or expert reviews can also be valuable for assessing quality.
3. Iterative Improvement: Based on the evaluation results, iterate on the model architecture, training process, or data preprocessing steps to improve performance. This may involve experimenting with different architectures, fine-tuning hyperparameters, or collecting additional data.
By following these steps for configuring the model architecture, training the model on collected data, and evaluating model performance iteratively, you can build a robust generative AI solution that meets your objectives effectively.
Optimizing the Model
Adjusting Hyperparameters and Loss Functions
When it comes to optimizing a generative AI model, fine-tuning hyperparameters and selecting appropriate loss functions are crucial steps. Here's how to navigate this process effectively:
1. Hyperparameters Adjustment: Hyperparameters are settings that control the learning process of the AI model. Experimenting with different values for parameters like learning rate, batch size, and regularization strength can significantly impact the model's performance. Here's how to approach it:
a. Learning Rate: This parameter determines the step size during the optimization process. Adjusting it can help speed up convergence or prevent overshooting. Start with a moderate value and gradually tune it based on the model's performance.
b. Batch Size: The number of data samples processed together during each iteration affects the stability and speed of training. Larger batch sizes may lead to faster convergence but require more memory. Experiment with different batch sizes to find the optimal balance between speed and stability.
c. Regularization Strength: Techniques like L1 or L2 regularization help prevent overfitting by penalizing overly complex models. Tuning the regularization strength can control the model's complexity and generalization ability.
2. Loss Function Selection: The choice of loss function depends on the specific task and desired model behavior. Common loss functions for generative AI include:
a. Mean Squared Error (MSE): Suitable for regression tasks, MSE measures the average squared difference between predicted and actual values. It's commonly used for tasks like image reconstruction or generation.
b. Binary Cross-Entropy: Ideal for binary classification problems, binary cross-entropy quantifies the difference between predicted and actual binary outcomes.
c. Categorical Cross-Entropy**: Used in multi-class classification tasks, categorical cross-entropy measures the discrepancy between predicted class probabilities and true class labels.
Techniques for Improving Model Accuracy and Efficiency
Achieving optimal model accuracy and efficiency requires implementing advanced techniques tailored to the specific characteristics of generative AI solutions. Here are some effective strategies to consider:
1. Architecture Optimization: Experiment with different neural network architectures and model configurations to find the optimal design for your generative AI task. Techniques like skip connections, residual blocks, and attention mechanisms can enhance model performance and efficiency.
2. Transfer Learning: Leveraging pre-trained models or transfer learning techniques can expedite the training process and improve accuracy, especially when working with limited data. Fine-tuning pre-trained models on task-specific datasets can help jumpstart training and yield better results.
3. Data Augmentation: Augmenting the training data with synthetic examples or applying transformations like rotation, translation, or noise injection can increase the diversity and robustness of the dataset. Data augmentation techniques help prevent overfitting and improve model generalization.
Addressing Overfitting and Underfitting Issues
Overfitting and underfitting are common challenges in model training that can hinder the performance of generative AI solutions. Here's how to tackle these issues effectively:
1. Overfitting Prevention: To combat overfitting, employ regularization techniques such as dropout, weight decay, or early stopping. These methods help prevent the model from memorizing the training data and encourage generalization to unseen examples.
a. Dropout: Randomly deactivate neurons during training to prevent reliance on specific features.
b. Weight Decay: Penalize large weights to discourage over-reliance on individual features.
c. Early Stopping: Halt training when performance on a validation set starts to degrade, preventing overfitting.
2. Underfitting Mitigation: If the model exhibits signs of underfitting, consider increasing model complexity by adding more layers, units, or parameters. Additionally, augmenting the training data or reducing regularization strength can help the model capture more complex patterns and improve performance.
a. Increasing Model Complexity: Add more layers, units, or parameters to capture complex patterns.
b. Augmenting Training Data: Introduce synthetic examples or apply transformations to enrich the dataset.
c. Reducing Regularization Strength: Relax regularization constraints to allow the model to learn more from the data.
By carefully adjusting hyperparameters, selecting appropriate loss functions, and implementing advanced optimization techniques, you can enhance the accuracy, efficiency, and robustness of your generative AI model. Addressing overfitting and underfitting issues ensures that your model generalizes well to unseen data and produces high-quality outputs consistently.

Deployment Considerations
As you embark on the journey of building a generative AI solution, it's crucial to consider deployment considerations to ensure its success in the real world. Deployment strategies, such as cloud-based or on-premises solutions, play a pivotal role in determining accessibility, scalability, and security. Selecting the right model server for hosting the trained model is essential for seamless integration into existing systems. Furthermore, prioritizing scalability, reliability, and security in deployment ensures a robust and efficient solution that meets the evolving needs of users.
Choosing a Deployment Strategy
Selecting the right deployment strategy is crucial for the success of your generative AI solution. Whether you opt for cloud-based deployment for flexibility and scalability or on-premises deployment for enhanced security and control, understanding your options is essential in ensuring optimal performance and accessibility.
Selecting a Model Server for Hosting the Trained Model
Once you've trained your generative AI model, choosing the right model server is key to making it accessible to users. Consider factors such as compatibility with your chosen framework, scalability options, and support for deployment environments. By selecting the appropriate model server, you can ensure smooth and efficient hosting of your trained model.
Ensuring Scalability, Reliability, and Security in Deployment
Scalability, reliability, and security are paramount when deploying a generative AI solution. Implementing scalable infrastructure ensures that your solution can handle increased user demand without compromising performance. Additionally, prioritizing reliability through robust monitoring and maintenance practices is essential for uninterrupted service. Finally, incorporating stringent security measures safeguards sensitive data and mitigates potential risks, ensuring a seamless and secure user experience.
Maintenance and Iteration
Maintenance and iteration are vital components in the lifecycle of any generative AI solution. Once deployed, these processes ensure the continued functionality, efficiency, and relevance of the AI model. Maintenance involves establishing a plan for regular updates, bug fixes, and security measures, while iteration focuses on incorporating user feedback and adapting to advancements in AI technology. In this section, we delve into the importance of maintenance and iteration, outlining strategies for effective implementation in building and maintaining generative AI solutions. Let’s dive deep into the topic.
Establishing a Maintenance Plan for Regular Updates and Improvements
1. Scheduled Updates: Set up regular intervals for updating your AI model and software. This could be weekly, monthly, or as needed based on the pace of advancements in generative AI technology.
2. Monitoring Performance: Implement monitoring tools to track the performance of your AI model in real-time. This includes metrics such as accuracy, efficiency, and user satisfaction.
3. Bug Fixes and Patching: Address any bugs or issues that arise promptly. Regularly release patches and updates to improve the stability and functionality of your generative AI solution.
4. Security Measures: Stay vigilant against potential security threats and vulnerabilities. Keep your software up-to-date with the latest security patches and protocols to safeguard against data breaches and malicious attacks.
5. Documentation and Knowledge Sharing: Maintain thorough documentation of your AI model and software to facilitate knowledge sharing among team members. This ensures continuity in maintenance efforts, even as team members come and go.
Incorporating User Feedback and Addressing Issues Post-Deployment
User feedback is invaluable for improving the performance and usability of your generative AI solution. Here's how to incorporate user feedback effectively:
1. Feedback Mechanisms: Implement mechanisms for users to provide feedback directly within the AI application. This could include surveys, feedback forms, or in-app prompts.
2. User Testing: Conduct regular user testing sessions to gather insights into how users are interacting with your AI solution. Use this feedback to identify pain points and areas for improvement.
3. Prioritizing Feedback: Prioritize user feedback based on its impact on the user experience and overall effectiveness of the AI solution. Focus on addressing critical issues first before tackling minor enhancements.
4. Iterative Development: Adopt an iterative approach to development, where updates and improvements are rolled out incrementally based on user feedback. This allows for continuous refinement of the AI solution over time.
Continuously Iterating on the Model Based on Advancements and Changing Requirements
Generative AI technology is rapidly evolving, with new advancements and techniques emerging regularly. Here's how to ensure your AI model stays ahead of the curve:
1. Staying Updated: Keep abreast of the latest developments in generative AI research and technology. Attend conferences, workshops, and webinars to stay informed about new techniques and methodologies.
2. Experimentation and Innovation: Encourage a culture of experimentation and innovation within your AI development company. Explore new approaches and methodologies to push the boundaries of what's possible with generative AI.
3. Adapting to Changing Requirements: Be flexible and adaptable in response to changing requirements and user needs. Continuously reassess your AI model's capabilities and adjust as necessary to meet evolving demands.
4. Collaboration and Knowledge Sharing: Foster collaboration and knowledge sharing within your Generative AI development company and with external partners. Exchange ideas, share insights, and leverage collective expertise to drive innovation in generative AI solutions.
By establishing a robust maintenance plan, incorporating user feedback, and staying abreast of advancements, you can ensure that your generative AI solution remains effective, efficient, and relevant in an ever-changing landscape.
What are the Best Practices to Follow for Building Generative AI Solutions?
Building generative AI solutions requires adherence to best practices to ensure success. From data quality to model architecture selection and optimization, each step plays a crucial role in the development process. By following established guidelines and staying updated with advancements, developers can create effective generative AI systems that meet their objectives. Let’s look at the practices to follow.
Data Quality and Relevance
High-quality and relevant data are essential for training accurate generative AI models. Ensuring the dataset is representative of the problem domain and free from biases or inconsistencies is crucial. Data augmentation techniques can also be used to increase diversity and improve model performance. Let’s read multiple aspects to keep in mind while checking data quality and relevance.
1. Importance of Data: The quality and relevance of data are paramount in training generative AI models. Ensure that the data collected is diverse, representative, and free from biases.
2. Data Collection: Use reputable sources to gather high-quality data relevant to your specific use case, whether it's images, text, or other forms of data.
3. Data Preprocessing: Implement rigorous preprocessing techniques to clean, normalize, and augment the data, enhancing its quality and improving the model's performance.
4. Continuous Evaluation: Regularly evaluate the quality and relevance of the data throughout the model's lifecycle, and update it as necessary to ensure continued effectiveness.
Model Architecture Selection and Optimization
Selecting the appropriate model architecture is critical for the success of generative AI solutions. Developers should consider factors such as data type, complexity of the task, and available resources when choosing between neural networks or evolutionary algorithms. Optimization techniques like hyperparameter tuning and regularization can further enhance model performance. Let’s read the points below.
1. Understanding Model Architectures: Gain a deep understanding of different generative AI model architectures, such as GANs, VAEs, and transformer-based models, to select the most suitable one for your specific task.
2. Start Simple: Begin with a basic model architecture and gradually refine and optimize it based on performance evaluation and feedback.
3. Hyperparameter Tuning: Experiment with different hyperparameters, such as learning rate, batch size, and regularization techniques, to optimize model performance.
4. Regular Updates: Keep abreast of the latest research and advancements in model architectures and optimization techniques, and incorporate them into your generative AI solution as appropriate.
Training, Evaluation, and Deployment Strategies
Effective training, evaluation, and deployment strategies are essential for building robust generative AI solutions. Developers should iterate on the model, track performance metrics, and deploy the system in a controlled environment before releasing it to users. Continuous monitoring and updates are necessary to ensure optimal performance post-deployment.
1. Structured Training Process: Develop a structured training process that includes iterative model training, evaluation, and validation using both quantitative metrics and qualitative assessments.
2. Evaluation Metrics: Define appropriate evaluation metrics based on the specific use case, such as image realism, text coherence, or music quality, to measure the performance of the generative AI model accurately.
3. Deployment Considerations: Select the appropriate deployment strategy, whether it's cloud-based, on-premises, or edge deployment, considering factors such as scalability, reliability, and security.
4. Continuous Monitoring: Implement robust monitoring mechanisms to track the performance of the deployed generative AI solution in real-world scenarios and make necessary adjustments and updates as needed.
Staying Updated with Advancements in the Field
Generative AI is a rapidly evolving field, with new techniques and models emerging regularly. Developers must stay updated with the latest research, attend conferences, and engage with the AI community to leverage advancements effectively. Incorporating cutting-edge technologies and methodologies can enhance the effectiveness of generative AI solutions.
1. Continuous Learning: Stay updated with the latest advancements in generative AI research, techniques, and tools through reading research papers, attending conferences, and participating in online forums and communities.
2. Experimentation: Encourage a culture of experimentation and innovation within your team, where members are encouraged to explore new ideas, techniques, and approaches to enhance generative AI solutions.
3. Collaboration: Foster collaboration with academia, industry partners, and other stakeholders to leverage collective knowledge and expertise in advancing generative AI solutions.
4. Ethical Considerations: Stay informed about ethical considerations and societal implications related to generative AI technologies, and ensure that your solutions are developed and deployed responsibly.
By adhering to these best practices, you can build robust and effective generative AI solutions that meet the diverse needs and challenges of various industries and applications.
Read More
1. A Complete Guide to Building a Chabot Using Gemini API
2. How to Choose the Right Generative AI Development Company?
Conclusion
In conclusion, this blog has provided a comprehensive guide on how to build generative AI solutions, covering key aspects from designing to deployment. By understanding the importance of generative AI in manufacturing and various industries, readers are empowered to embark on their AI journey confidently. With the insights gained on how to build AI models and applications, create AI software, and develop AI systems, individuals and businesses alike can harness the power of generative AI to produce innovative solutions. Let's continue exploring the endless possibilities and advancements in the field of AI, driving transformative changes in technology and beyond.
FAQs
1. How to build an AI model?
Build an AI model by collecting data, choosing an architecture, training, evaluating, and deploying it using tools like TensorFlow or PyTorch.
2. How to build an AI application?
Develop an AI application by defining objectives, selecting algorithms, gathering data, training models, testing, and deploying using frameworks like Flask or Django.
Meet the Author

Sanjeev Verma
Sanjeev Verma, the CEO of Biz4Group LLC, is a visionary leader passionate about leveraging technology for societal betterment. With a human-centric approach, he pioneers innovative solutions, transforming businesses through AI Development, IoT Development, eCommerce Development, and digital transformation. Sanjeev fosters a culture of growth, driving Biz4Group's mission toward technological excellence. He’s been a featured author on IBM and TechTarget.
Linkedin - https://www.linkedin.com/in/sanjeev1975/


